共计 1090 个字符,预计需要花费 3 分钟才能阅读完成。
近年来,大型科技公司不断推出规模越来越大的 AI 模型,这些模型依赖昂贵的 GPU 提供生成式 AI 云服务。然而,小型 AI 模型同样具有重要价值。近日,Google 宣布推出一款小巧的 Gemma 开放模型,专为在本地设备上运行而设计。尽管体积小巧,但新的 Gemma 3 270M 模型在性能上依然表现出色,且能够快速调整。
今年早些时候,Google 发布了其首个 Gemma 3 开放模型,参数范围在 10 亿到 270 亿之间。在生成式 AI 中,参数是控制模型处理输入以估计输出的学习变量。通常,模型中的参数越多,性能越好。然而,新的 Gemma 3 仅有 2.7 亿个参数,能够在智能手机等设备上运行,甚至完全在 Web 浏览器中运行。

- 
- 
- 
- 
- 
- 
- 
- 
- 
- 
在本地运行 AI 模型有许多优势,包括增强隐私和降低延迟。Gemma 3 270M 正是为这些用例设计的。在 Pixel 9 Pro 的测试中,新的 Gemma 能够在 Tensor G4 芯片上运行 25 次对话,仅消耗设备 0.75% 的电量,成为迄今为止最高效的 Gemma 模型。
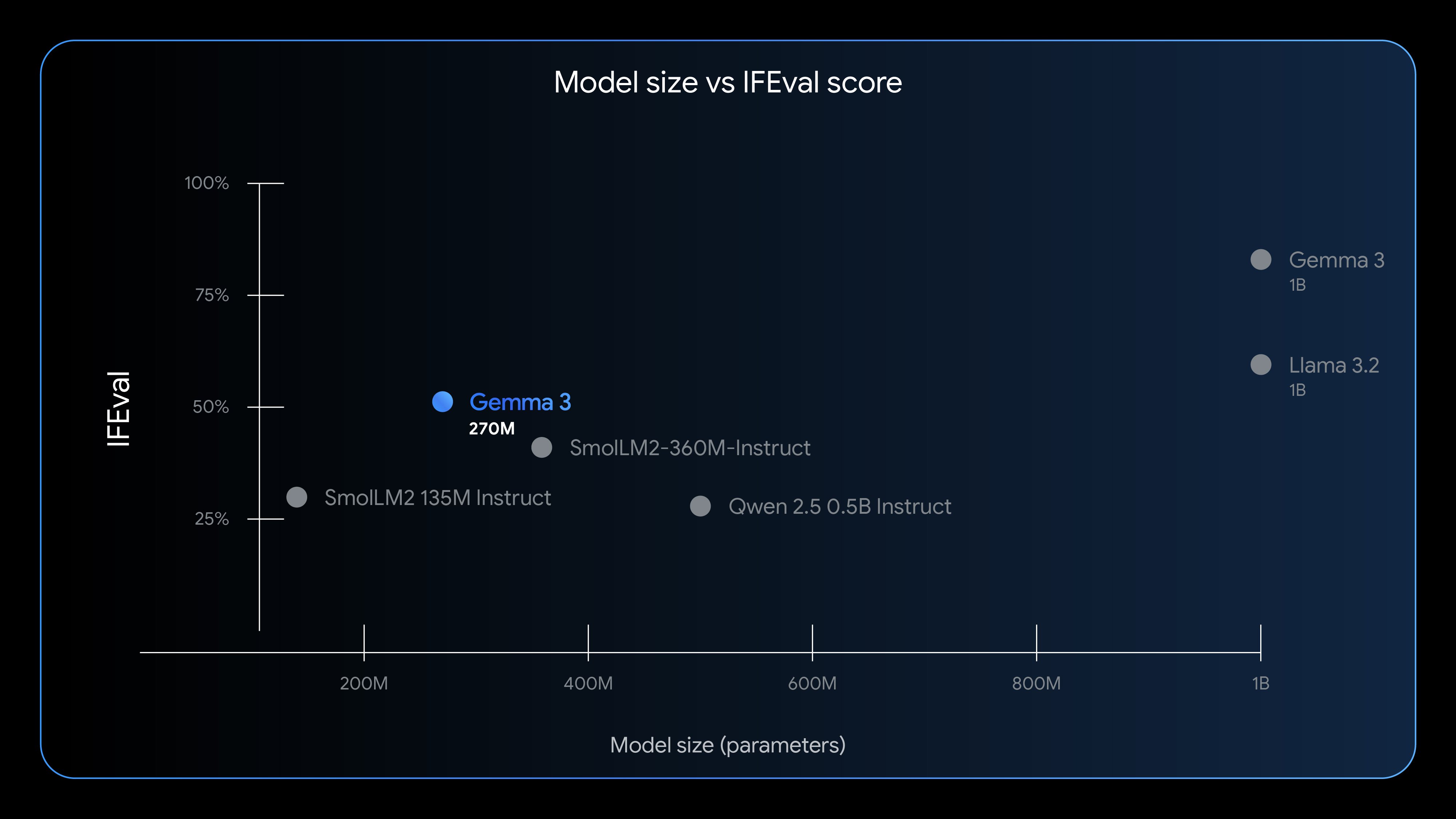
尽管开发者不应期望其与数十亿参数模型相同的性能水平,但 Gemma 3 270M 有其独特的用途。Google 使用 IFEval 基准测试了模型跟随指令的能力,结果显示其新模型的表现超出其体积。Gemma 3 270M 在该测试中得分为 51.2%,高于其他参数更多的轻量级模型。虽然新的 Gemma 显然不及 Llama 3.2 等 10 亿以上参数的模型,但其表现比预期的更接近。
Google 声称,Gemma 3 270M 在开箱即用的情况下擅长跟随指令,但预计开发者会针对其特定用例进行微调。由于参数数量少,该过程快速且成本低。Google 认为新的 Gemma 可用于文本分类和数据分析等任务,这些任务可以快速完成,且无需大量计算资源。
Google 将 Gemma 模型称为“开放”,但这不应与“开源”混淆。不过,大多数情况下情况相同。开发者可以免费下载新的 Gemma,模型权重也可用。没有单独的商业许可协议,因此开发者可以在其工具中修改、发布和部署 Gemma 3 270M 的衍生版本。
然而,使用 Gemma 模型的任何人都受使用条款的约束,这些条款禁止调整模型以产生有害输出或故意违反隐私规则。开发者还需详细说明修改内容,并为所有衍生版本提供使用条款的副本,这些版本继承 Google 的自定义许可。
Gemma 3 270M 可从 Hugging Face 和 Kaggle 等平台获取,提供预训练和指令调整版本。它也可在 Google 的 Vertex AI 中进行测试。Google 还通过基于 Transformer.js 构建的完全基于浏览器的故事生成器展示了新模型的能力。即使对开发新的轻量级模型不感兴趣,也可以尝试一下。



